

La carrera por modelos cada vez más capaces tiene un problema menos vistoso que los parámetros: la memoria. Con TurboQuant Google IA, la firma plantea una forma de comprimir uno de los puntos más caros de la inferencia sin castigar la precisión. La idea no gira en torno a un truco menor, sino a una familia de algoritmos pensada para contextos largos y búsquedas sobre vectores. Si funciona fuera del papel como promete, el impacto se notará en coste, velocidad y escala.
Google Research presenta TurboQuant como su método principal, acompañado por QJL y PolarQuant. El foco está en la KV cache, esa memoria rápida que evita recalcular información intermedia mientras el modelo genera texto. Cuanto mayor es el contexto, más pesa esa carga en hardware y presupuesto. Ahí es donde este anuncio gana relevancia para cualquier despliegue serio de IA generativa.
TurboQuant Google IA pone el foco en la KV cache
La propuesta de Google parte de un cuello de botella conocido, aunque pocas veces explicado fuera del ámbito técnico. Los modelos no solo consumen recursos por su tamaño, también por la cantidad de datos temporales que mueven durante cada respuesta. Esa presión se dispara cuando hay ventanas de contexto amplias o tareas que consultan grandes bases vectoriales. En ese escenario, comprimir la memoria deja de ser un ajuste fino y pasa a ser una necesidad operativa.
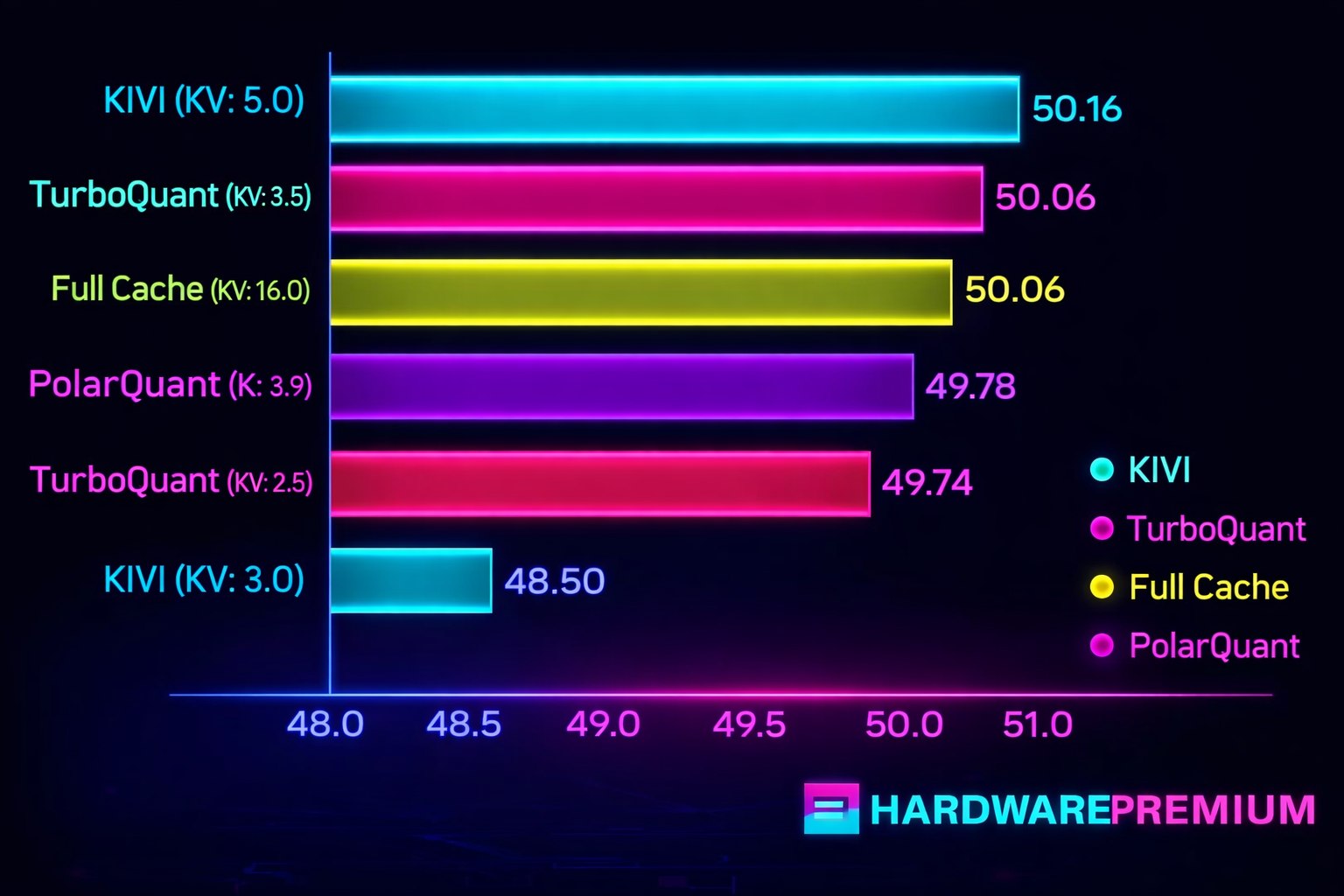
Según la compañía, TurboQuant puede llevar la KV cache hasta esquemas de 3 bits en ciertos escenarios. El dato importa porque los formatos habituales son bastante más pesados y castigan tanto la capacidad como el ancho de banda. Google asegura además que el rendimiento del modelo se mantiene en pruebas hechas con Gemma, Mistral y Llama. No es una promesa pequeña, porque reducir memoria suele implicar perder precisión o estabilidad.
Junto al método principal aparecen QJL y PolarQuant como piezas complementarias dentro de la misma arquitectura. La compañía las sitúa como apoyo para mantener la eficiencia en operaciones de atención y recuperación de información. En aceleradores H100, Google habla de mejoras de hasta 8 veces frente a claves sin cuantizar. Esa cifra necesita validación independiente, pero sirve para medir la ambición del proyecto.
Menos memoria cambia el coste real de servir modelos
Lo interesante de TurboQuant Google IA no es solo el dato técnico, sino lo que puede mover en la práctica. Menos memoria significa más sesiones simultáneas en la misma infraestructura y menos presión sobre el hardware. También abre la puerta a contextos más largos sin disparar la factura de inferencia. Para empresas que sirven millones de consultas, esa ecuación pesa tanto como la calidad del propio modelo.
Puedes seguir a HardwarePremium en Facebook, Twitter (X), Instagram, Threads, BlueSky o Youtube. También puedes consultar nuestro canal de Telegram para estar al día con las últimas noticias de tecnología.
FAQ
TurboQuant se centra en la KV cache, la memoria temporal que el modelo usa para no recalcular datos durante la generación de texto.
Sí. La compañía menciona pruebas con Gemma, Mistral y Llama, manteniendo el rendimiento según sus datos.
Reducir memoria puede bajar costes de inferencia, permitir más usuarios simultáneos y acelerar respuestas en contextos largos.
Son técnicas complementarias dentro de la propuesta de Google para mejorar compresión y eficiencia en operaciones relacionadas con atención y vectores.
 Esta AIO NO necesita cables… pero hay truco
Esta AIO NO necesita cables… pero hay truco Dejé de repetir tomas gracias a este teleprompter
Dejé de repetir tomas gracias a este teleprompter ¿La silla que iguala a un Herman Miller… con motor y masaje incluido?
¿La silla que iguala a un Herman Miller… con motor y masaje incluido? FANATEC CLUBSPORT FORMULA V3, ¿lo que esperábamos?
FANATEC CLUBSPORT FORMULA V3, ¿lo que esperábamos? ASUS ROG ZEPHYRUS DUO 16 2026, diseño único y máxima potencia
ASUS ROG ZEPHYRUS DUO 16 2026, diseño único y máxima potencia

Comentarios