

DRAM y latencia rara vez aparecen juntas fuera de una discusión de rendimiento fino, pero aquí van de la mano: LaurieWired ha mostrado un método, llamado TailSlayer, que reduce la peor latencia de acceso a memoria hasta un 93,3% en algunos sistemas. El truco consiste en esquivar los parones provocados por los refrescos de DRAM haciendo que dos núcleos compitan entre sí y se quede el que termine antes.
El dato importa porque no hablamos de un microajuste menor. En cargas muy sensibles a la variación de latencia, unos cientos de nanosegundos cambian el resultado. Y cuando un acceso cae justo en un ciclo de refresco, el sistema se queda esperando; en chips modernos, esa pausa puede traducirse en miles de ciclos perdidos.
La contrapartida también está clara desde el principio: el método exige duplicar el conjunto de trabajo y repartirlo por canales de memoria distintos. Es decir, se intercambia capacidad y núcleos por determinismo. Para la mayoría de usos no encaja, pero en tareas donde cada microsegundo cuenta, el balance cambia bastante.
Cómo TailSlayer esquiva los stalls de DRAM con dos núcleos
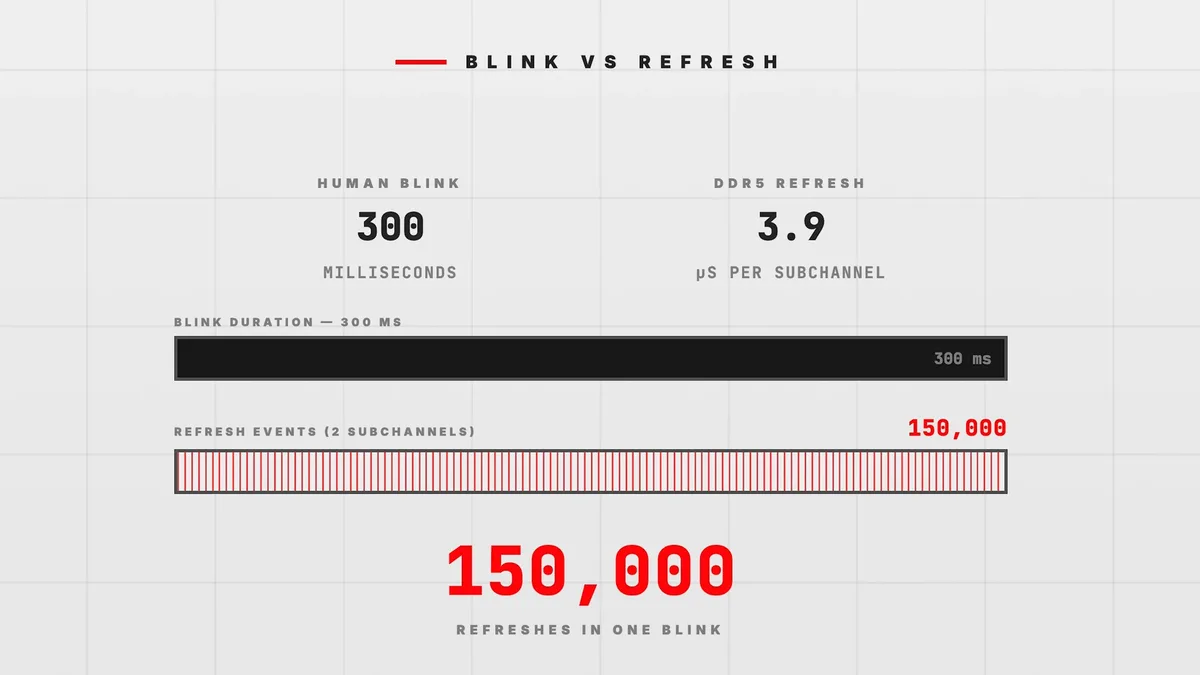
La base técnica es sencilla de explicar y más complicada de ejecutar. DRAM necesita refrescarse de forma constante porque sus celdas almacenan datos en condensadores con fugas. Ese refresco no va sincronizado con cada acceso, así que un hilo puede toparse con memoria ocupada y quedarse bloqueado hasta que termine la operación.
LaurieWired empezó intentando prever esos refrescos y sincronizarse con ellos, pero esa vía no funcionó. Después probó con paralelismo en un solo núcleo, aunque la caché y los reorder buffers reducían parte del problema. La solución llegó al mover la pelea a dos núcleos distintos, con dos copias del mismo trabajo y cada una en un canal físico diferente.
El resultado es un sistema de hedging: ambos caminos avanzan a la vez y gana el que complete la tarea primero. Si uno choca con un refresco de DRAM, el otro tiene bastante papeletas para no hacerlo al mismo tiempo. En su Ryzen de consumo, la técnica recortó la peor latencia de acceso a memoria en más de la mitad.

Un 89% menos en EPYC Turin y un 93,3% en Xeon
La cosa sube de nivel en hardware de servidor. En instancias alquiladas en AWS, LaurieWired probó la técnica sobre máquinas AMD, Intel y Arm. En un EPYC Turin, con doce canales de memoria, el esquema de cobertura entre canales redujo la latencia cercana al peor caso un 89%.
El resultado más llamativo llegó en Intel Xeon de las familias Sapphire Rapids y Diamond Rapids. Ahí, TailSlayer logró mejoras de hasta el 93,3%, pasando de 1697 ns a 113 ns en el percentil p99.99. La cifra no es menor: la propia gráfica mostraba un mínimo en torno a 105 ns, así que el Xeon quedó muy cerca de su mejor escenario medido.
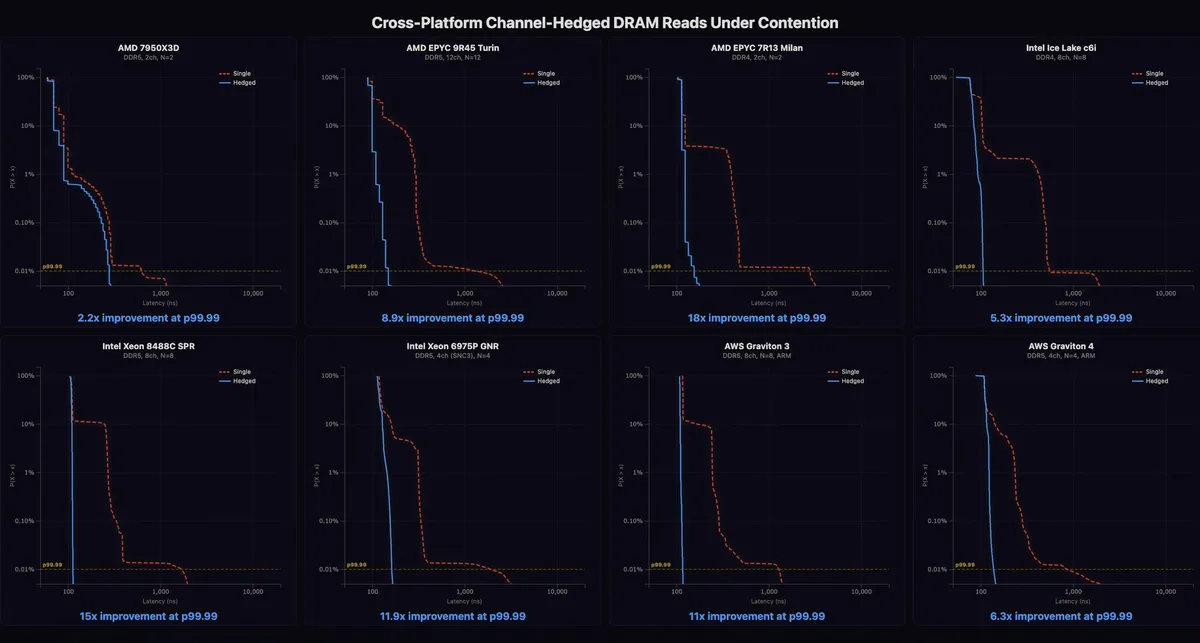
Ese tipo de estabilidad tiene sentido sobre todo en alta frecuencia de negociación, microservicios de alto QPS, motores de emparejado o estructuras concurrentes muy ajustadas. También podría servir en simuladores o servidores de juego con precisión alta. En todos esos casos, un refresco de DRAM en el momento menos oportuno puede costar una operación entera.
La otra cara: multiplicar memoria para ganar determinismo
El límite del enfoque es duro. Si se quiere hedging en varios canales, hay que duplicar el working set para cada canal implicado. LaurieWired lo reconoce en su vídeo de 54 minutos: la mejora llega a costa de memoria y CPU, y eso deja fuera a la mayoría de cargas.

El dato práctico es ese. Un recorte del 93% en la peor latencia de DRAM suena enorme, pero viene acompañado por un aumento del consumo de recursos que puede multiplicar la memoria necesaria por el número de canales usados. Por eso el método encaja en escenarios muy concretos y deja fuera el uso generalista.
El trabajo también tuvo un componente de ingeniería poco trivial: reverse-engineering de comportamientos de scrambing de memoria no documentados y adaptación a CPUs Arm Graviton, donde no están disponibles los mismos contadores de hardware que en x86-64. El código de demostración está en su GitHub, y la idea ya deja una conclusión bastante clara: el cuello de botella de DRAM sigue ahí, pero ahora hay una forma de rodearlo cuando la latencia peor caso es más importante que la capacidad.
Ese matiz conecta con otro frente del mercado. Mientras se buscan trucos para exprimir la memoria, los precios siguen tensándose, como vimos en la subida del 30% de Samsung en memorias DRAM para el segundo trimestre de 2026 [https://www.hardwarepremium.com/noticias/39515/samsung-eleva-30-precios-sus-memorias-dram-segundo-trimestre-2026/] y en el análisis de la crisis de contratos y precios de 2026 [https://www.hardwarepremium.com/noticias/35061/crisis-memoria-dram-contratos-precios-2026/].
Puedes seguir a HardwarePremium en Facebook, Twitter (X), Instagram, Threads, BlueSky o Youtube. También puedes consultar nuestro canal de Telegram para estar al día con las últimas noticias de tecnología.
FAQ
Es un método de software creado por LaurieWired para reducir la peor latencia de acceso a DRAM. Lo hace duplicando el trabajo en dos núcleos y dejando que gane el acceso que termine antes.
En un Ryzen de consumo, la mejora superó la mitad de la latencia de cola. En servidores, el método llegó al 89% en EPYC Turin y al 93,3% en Xeon.
Porque necesita refrescar sus celdas de forma periódica. Si un acceso coincide con ese refresco, el sistema se detiene hasta que termina el ciclo.
Porque exige duplicar el conjunto de trabajo y usar más recursos para ganar determinismo. Ese coste de memoria y CPU la deja reservada para usos muy concretos, como HFT o sistemas de alta precisión.



Comentarios