

La optimización de AVX-512 para RAID en Linux está mostrando hasta un 41% de mejora en un AMD Ryzen 9 9950X. El cambio consiste en añadir una implementación de xor_gen() con vectores de 512 bits y usar vpternlogq cuando toca hacer XOR de tres entradas.
La cifra importa porque no hablamos de un ajuste teórico. La aceleración aparece en hardware x86_64 compatible con AVX512F y sin la condición PREFER_YMM, justo el terreno donde se mueve una parte concreta de CPUs de AMD e Intel.
Qué CPUs pueden usar esta optimización de AVX-512
La activación de esta ruta se limita a procesadores que cumplan AVX512F && !PREFER_YMM. En la práctica, eso incluye:
- AMD Zen 4 y posteriores, tanto en cliente como en servidor.
- Intel Sapphire Rapids y posteriores, en servidor.
- Intel Rocket Lake, en cliente.
- Intel Nova Lake y posteriores, en cliente.
La exclusión de PREFER_YMM deja fuera las implementaciones antiguas de AVX-512 en Intel Skylake Server e Intel Ice Lake. Esas CPUs podrían ejecutar el código, pero el criterio evita un comportamiento que se asocia a una bajada de frecuencia demasiado agresiva cuando se usan registros ZMM.
La política aplicada es la misma que ya se usa en el código de crypto y CRC. No hay más misterio: se prioriza el rendimiento real sobre una compatibilidad más amplia en silicio que no encaja con esta ruta.
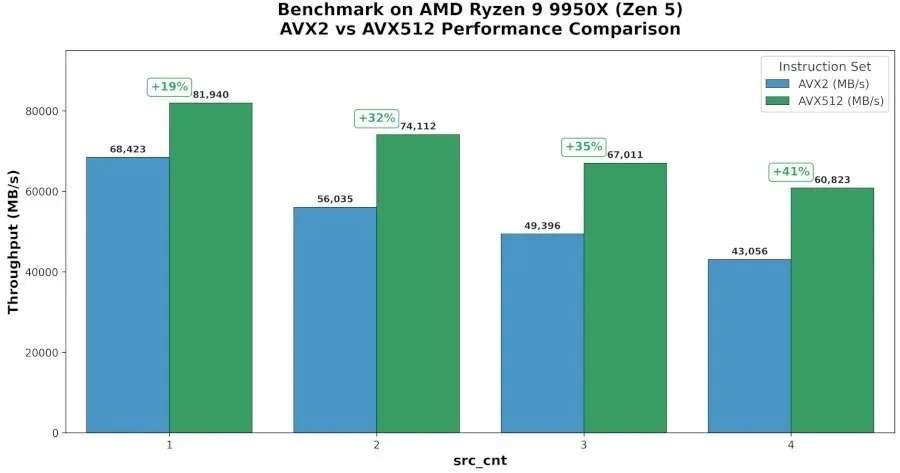
Por qué el salto del 41% interesa al rendimiento de Linux RAID
El dato del 41% no sale de una mejora general del sistema, sino de una pieza concreta del stack de RAID en Linux. Aun así, es una subida llamativa para una función tan específica, sobre todo en un Ryzen 9 9950X, que sirve como referencia del comportamiento en AMD Zen 4.
También encaja con otras piezas que ya hemos visto en el lado de Linux y AMD, como los parches de AMD para migración de páginas en Linux o el trabajo previo sobre AVX-512 en Linux para Zen 6. Aquí el foco es más concreto: exprimir RAID con una ruta vectorial más ancha.
El siguiente paso pasa por más pruebas independientes
Por ahora, la referencia sólida es esa mejora de hasta el 41% en el Ryzen 9 9950X y la lista de CPUs compatibles. Falta ver hasta dónde escala el comportamiento en otras cargas de RAID y en más modelos de AMD e Intel.
El dato ya deja una idea clara: cuando Linux puede tirar de AVX-512 sin penalización por frecuencia, ciertas tareas de almacenamiento cambian bastante de ritmo. Y esta optimización apunta justo a ese escenario.
Puedes seguir a HardwarePremium en Facebook, Twitter (X), Instagram, Threads, BlueSky o Youtube. También puedes consultar nuestro canal de Telegram para estar al día con las últimas noticias de tecnología.
FAQ
La fuente habla de una mejora de hasta el 41% en un AMD Ryzen 9 9950X. El cambio afecta a una implementación de xor_gen() en el código de RAID.
Se activa en CPUs x86_64 con AVX512F && !PREFER_YMM. Eso incluye AMD Zen 4 y posteriores, Intel Sapphire Rapids y posteriores, Intel Rocket Lake e Intel Nova Lake y posteriores.
Porque Skylake Server e Ice Lake pueden ejecutar el código, pero se asocian a una bajada de frecuencia demasiado agresiva al usar registros ZMM. La política busca evitar ese comportamiento.
vpternlogq se usa cuando hace falta resolver XOR de tres entradas. Forma parte de la implementación AVX-512 añadida para acelerar la ruta de RAID en Linux.



Comentarios