

El costo de la inteligencia artificial ha estado subiendo de forma constante, y no solo por la complejidad de los modelos, sino también por la dependencia que tienen en componentes como la memoria y el almacenamiento. A medida que los modelos de lenguaje se vuelven más grandes y sofisticados, la demanda de recursos computacionales también crece. Google, una de las empresas más activas en el desarrollo de IA, ha presentado una solución llamada TurboQuant, una innovación que podría cambiar la forma en que se manejan estos recursos.
Cómo Google aborda el costo de la inteligencia artificial y por qué preocupa
La inteligencia artificial es un sistema que consume mucha memoria. Cada vez que un modelo de lenguaje procesa una consulta, necesita comparar la entrada del usuario con una base de datos interna. Esta comparación se hace mediante un proceso llamado ‘similitud’, donde se buscan coincidencias entre lo que el usuario escribe y los datos almacenados en la memoria. El resultado de esa búsqueda determina qué respuesta se le dará al usuario.
El problema es que este proceso requiere mucha memoria, especialmente cuando se trata de modelos grandes. Para evitar que la operación se vuelva lenta, las máquinas suelen almacenar en la memoria los resultados de consultas recientes. Esto se conoce como ‘cache de claves y valores’ o ‘KV cache’, y es uno de los principales consumidores de memoria en los sistemas de IA.
Con los precios de los componentes de almacenamiento en constante aumento, el costo de mantener modelos de IA grandes se ha convertido en un desafío importante. Google ha reconocido este problema y ha desarrollado TurboQuant como una forma de reducir el uso de memoria, lo que a su vez podría reducir los costos asociados.
¿Qué es TurboQuant y cómo funciona?
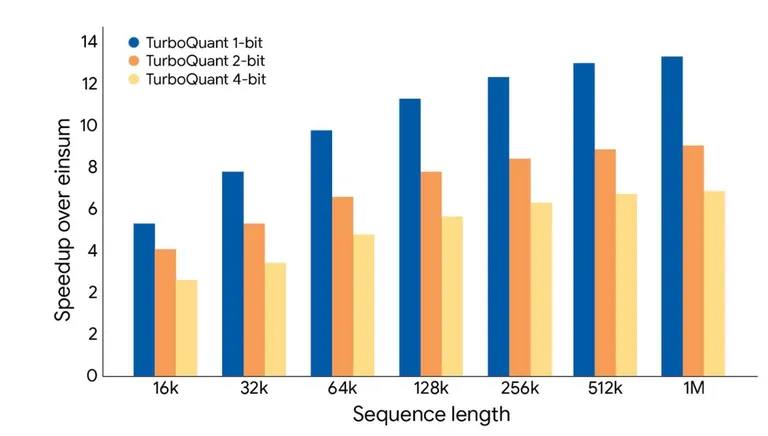
TurboQuant es una técnica de compresión de datos que reduce la cantidad de bits y bytes necesarios para representar la información en los modelos de IA. La idea detrás de esta tecnología es similar a la compresión de imágenes o videos, donde se elimina información redundante sin perder la esencia del contenido.
En el caso de TurboQuant, la tecnología se enfoca en el ‘KV cache’, el componente que más consume memoria. Al reducir la cantidad de datos que se almacenan en este cache, se puede mejorar la eficiencia del modelo, lo que significa que puede procesar más consultas con menos recursos.
Esta mejora no solo reduce el costo de operar modelos grandes, sino que también puede permitir que estos modelos se ejecuten en dispositivos locales, como computadoras personales o teléfonos móviles, sin necesidad de recurrir a servidores en la nube. Esto podría hacer que la IA sea más accesible para usuarios individuales y empresas que no tienen acceso a infraestructura avanzada.
Las limitaciones de TurboQuant y su impacto en el futuro de la IA
A pesar de sus beneficios, TurboQuant no es una solución definitiva. Algunos expertos señalan que, al hacer más eficiente a la IA, se podría terminar usando más de ella. Este fenómeno se conoce como el ‘paradoja de Jevons’, donde una mejora en la eficiencia lleva a un aumento en el consumo total del recurso.
Puedes seguir a HardwarePremium en Facebook, Twitter (X), Instagram, Threads, BlueSky o Youtube. También puedes consultar nuestro canal de Telegram para estar al día con las últimas noticias de tecnología.
FAQ
¿Por qué es importante reducir el uso de memoria en la IA?
La memoria es uno de los componentes más costosos en la computación moderna. Al reducir su uso, se puede disminuir el costo de operar modelos de IA grandes, lo que puede hacerlos más accesibles para empresas y usuarios individuales.
¿Qué es el ‘KV cache’ y por qué es relevante?
El ‘KV cache’ es una parte de la memoria que almacena resultados de consultas recientes en modelos de IA. Es relevante porque es uno de los principales consumidores de memoria, lo que lo convierte en un objetivo clave para la optimización.
¿Cómo afecta TurboQuant al futuro de la IA?
TurboQuant puede permitir que los modelos de IA se ejecuten en dispositivos locales, lo que podría hacerlos más accesibles. Sin embargo, también puede llevar a un aumento en el uso general de la IA, según el fenómeno conocido como ‘paradoja de Jevons’.



Comentarios